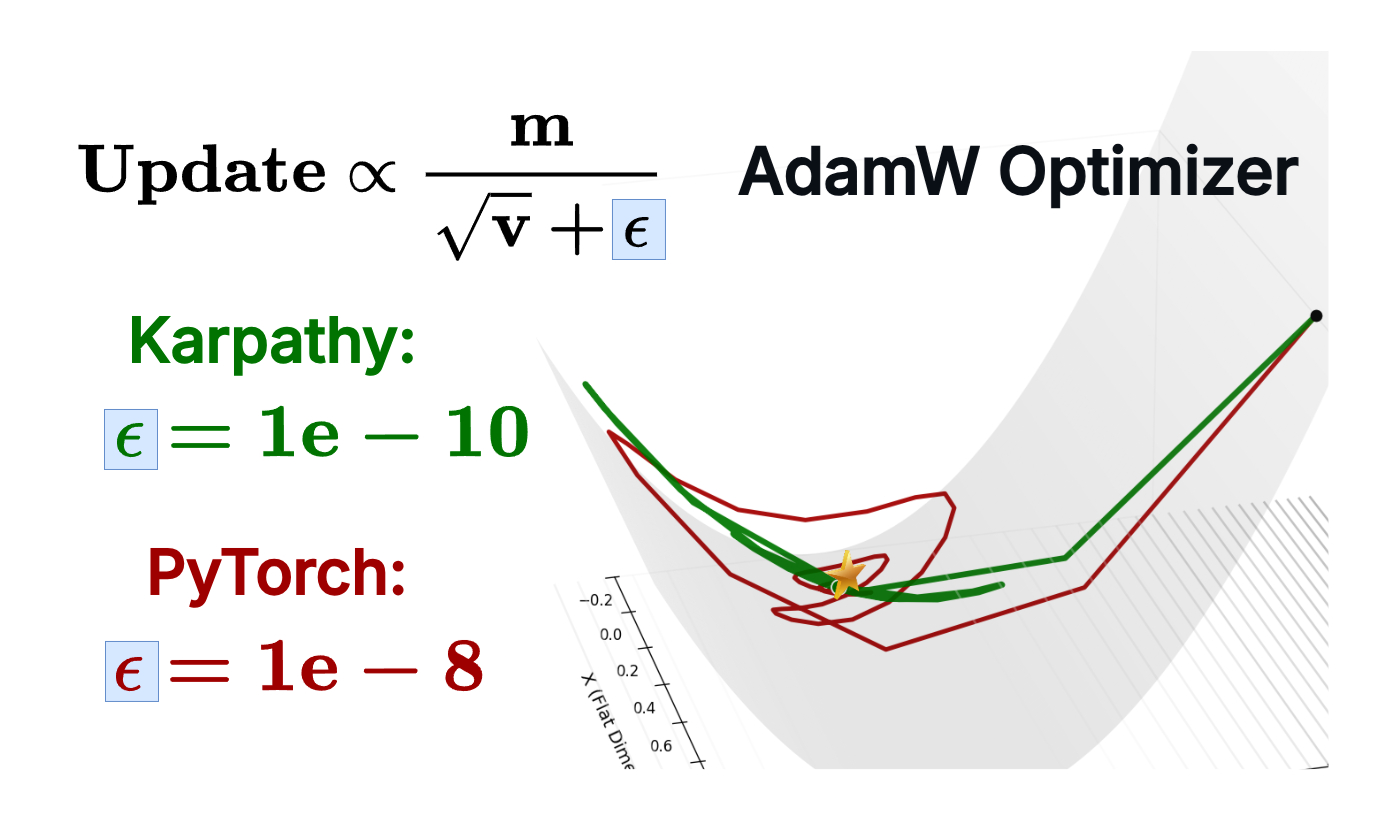
The Epsilon Trap: When Adam Stops Being Adam
Beyond numerical stability, we investigate an often overlooked hyperparameter in the Adam optimizer: epsilon.
Beyond numerical stability, we investigate an often overlooked hyperparameter in the Adam optimizer: epsilon.
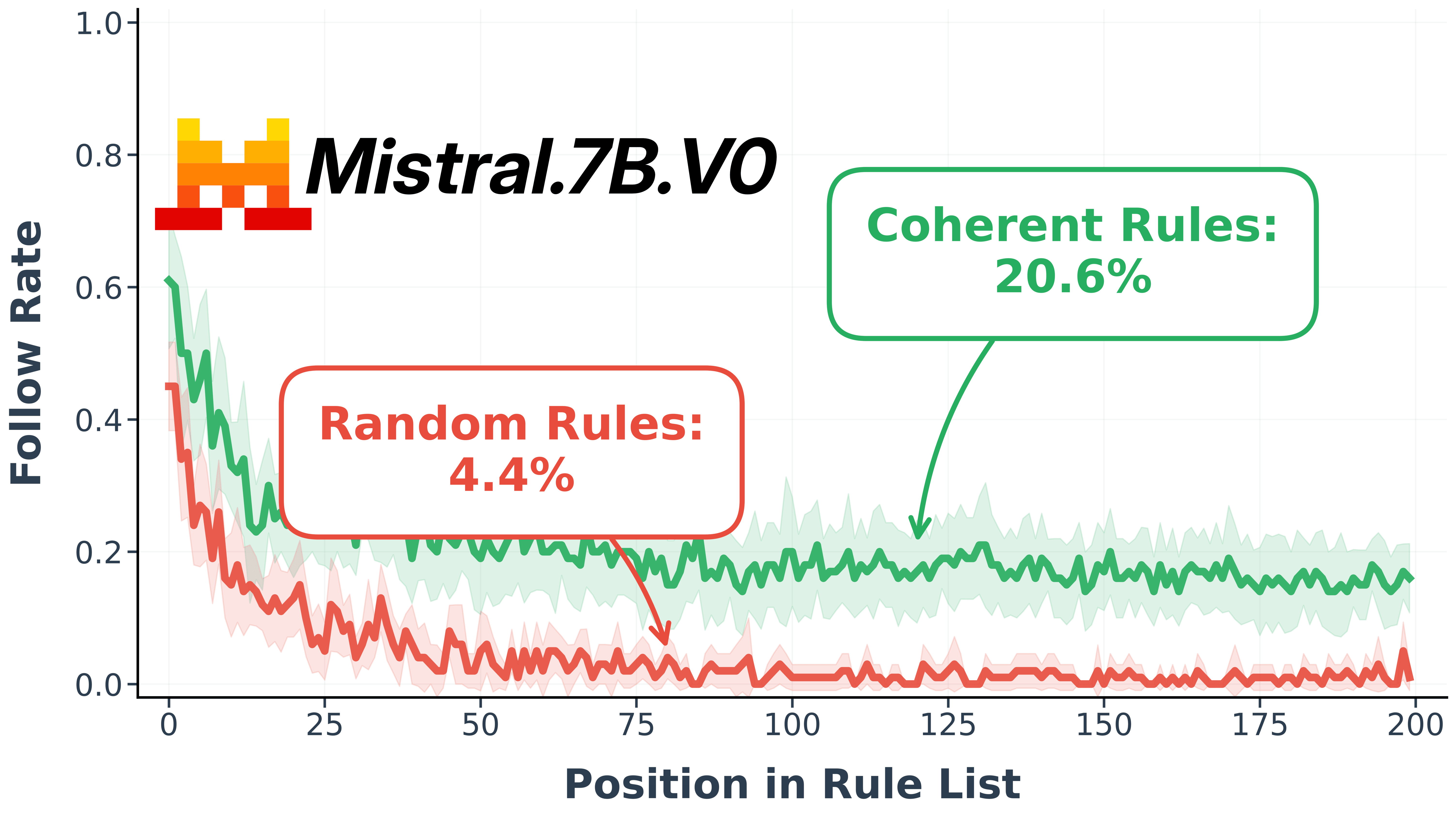
Testing whether semantic relatedness of instructions affects a model's ability to follow them under cognitive load
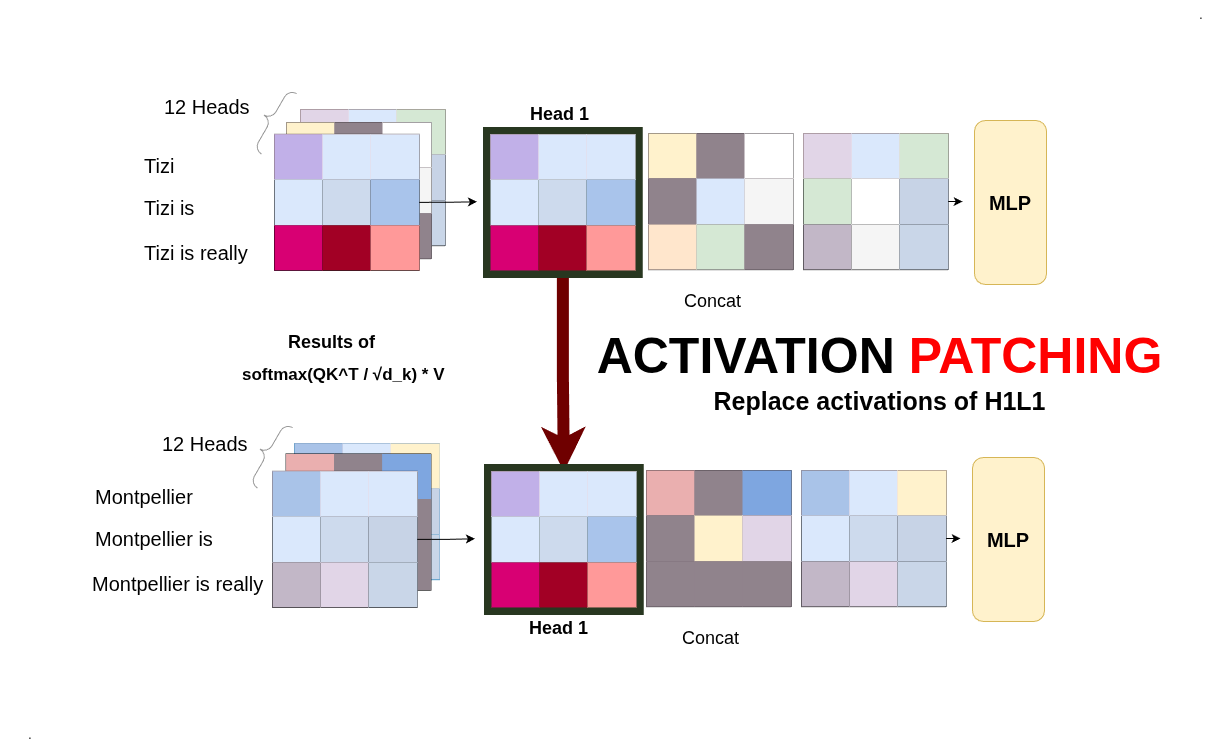
We strip down mechanistic interpretability to three key experiments: watching a model 'think', finding where it stores concepts, and performing 'causal surgery' to change its 'thought process'
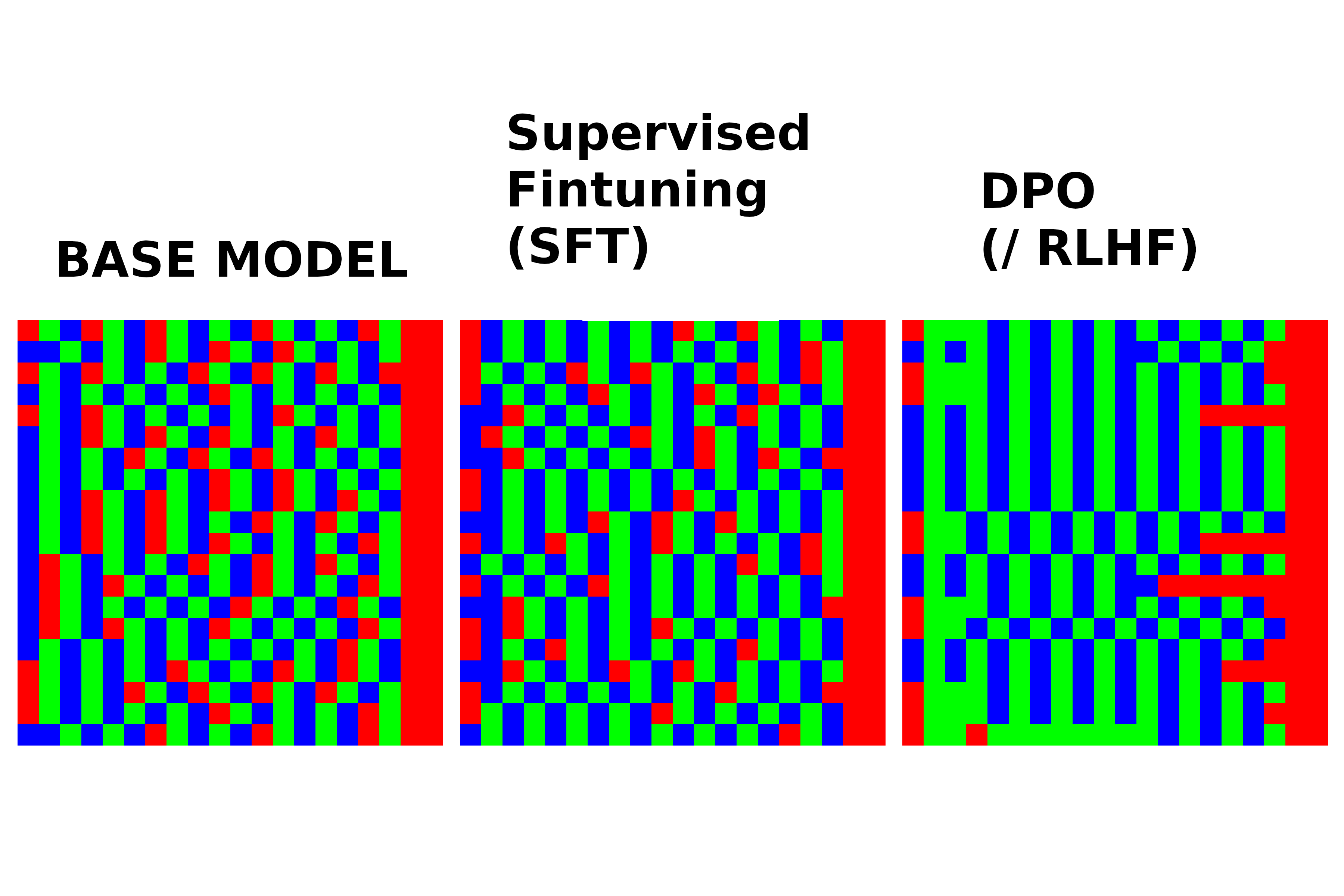
A visual guide and toy experiment to build intuition for the practical differences between Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO).
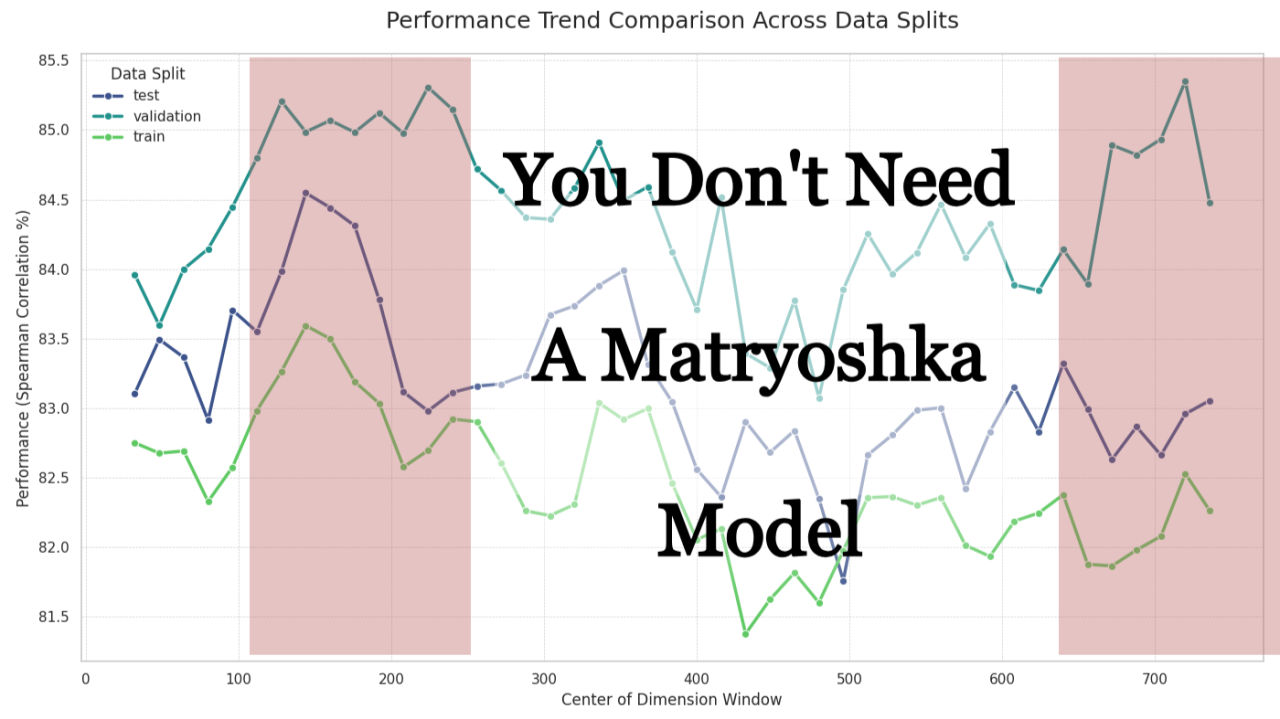
An analysis conducted on the informations hotspots on embeddings.

Flash Attention played a major role in making LLMs more accessible to consumers. This algorithm embodies how a set of what one might consider "trivial ideas" can come together and form a powerful s...

You've probably heard of the Transformers by now, they're everywhere, so much so that new born babies are gonna start saying Transformers as their first word, this blog will explore an important co...
If you're familiar with the Attention Mechansim, then you know that before applying a softmax to the attention scores, we need to rescale them by a factor of $\frac{1}{\sqrt{D_k}}$ where $D_k$ is t...
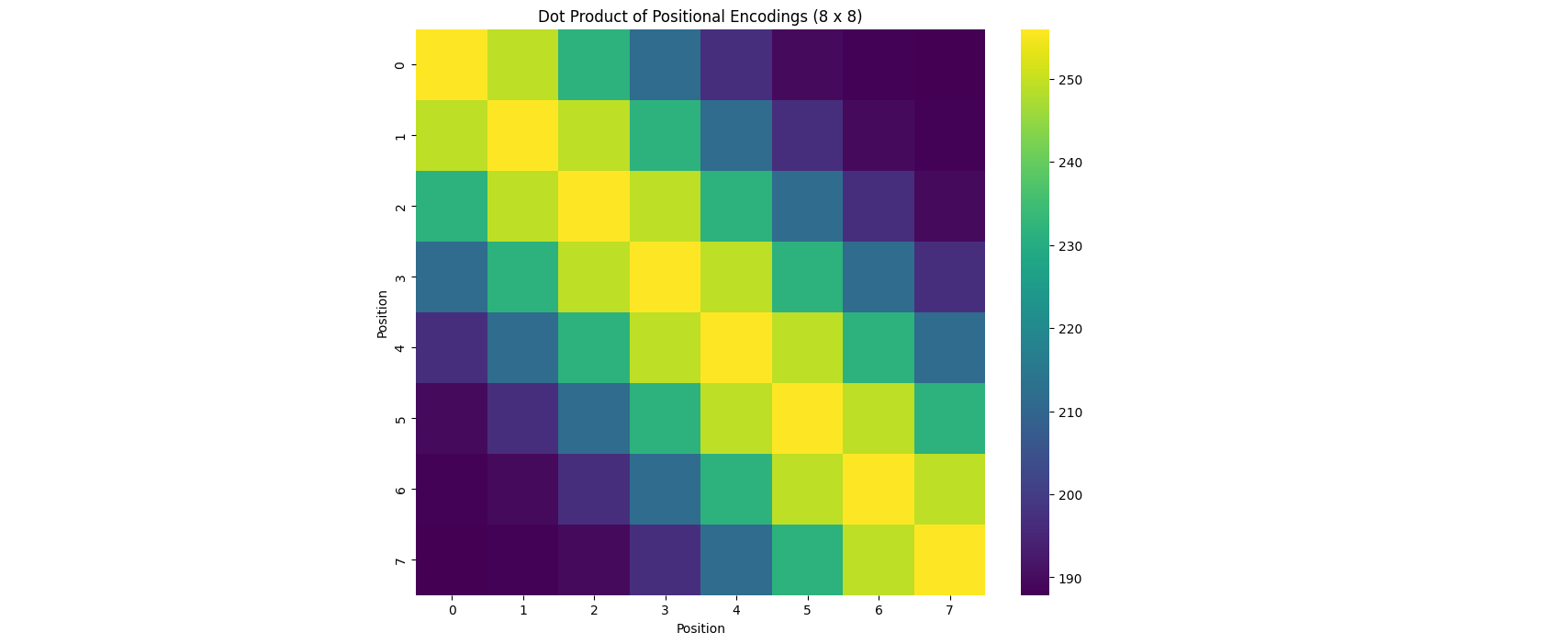
In this blog we will shed the light into a crucial component of the Transformers architecture that hasn't been given the attention it deserves, and you'll also get to see some pretty vizualizations!

A comprehensive guide to chunking strategies for Retrieval-Augmented Generation, from basic splitting to advanced semantic and agentic approaches.