Guidance – Structuring your outputs is easier than you think
In this post, we explore how to simplify and optimize the output generation process in language models using guidance techniques. By pre-structuring inputs and restraining the output space, we can enhance both the accuracy and efficiency of predictions.
Structure isn’t inherent
Relying on LLMs can be challenging for tasks that require strict adherence to specific rules. Despite being pretrained on vast amounts of data to develop raw “understanding” and undergoing supervised fine-tuning to follow certain formats (e.g., chat templates), LLMs remain probabilistic models. This inherently introduces a non-negligible risk of failing to obey precisely defined rules. This issue is particularly pronounced in smaller models optimized for end-user setups (typically those with fewer than tens of billions of parameters, though optimization techniques like quantization can raise this threshold). Consequently, devising strategies to enforce these rules becomes essential.

A common initial approach might involve parsing outputs using techniques like regex patterns. However, problematic outputs can take many forms. A frequent issue is the inclusion of unnecessary information. The vast space of possible variations (e.g., curly brackets in the middle of a description) makes it difficult to formulate comprehensive patterns. Moreover, this approach is inelegant and inefficient, as it wastes computational resources to generate outputs only to expend further resources filtering them.
A Refresher on Next-Token Sampling
Most language models can be divided into two main components. The first processes an input sequence, performing transformations (“reasoning”) to generate a raw representation. The second component projects this representation into a probability distribution over the vocabulary.


The challenge lies in the size of the vocabulary, which represents the number of possible items to select from. This size has been steadily increasing, as a larger vocabulary allows for greater expressiveness. While this expansion benefits general-purpose applications, it significantly complicates tasks that require focused or constrained outputs.
For example, the original LLaMA-3.2 has a vocabulary size of 128k, compared to LLaMA 2’s 32k—a fourfold increase.
Doing More with Less
The problem arises from demanding too much of these models. Instead, we might consider asking them to predict only the necessary content. This is the idea behind guidance—incorporating predefined rules into the generation process. Here’s how it can be achieved:
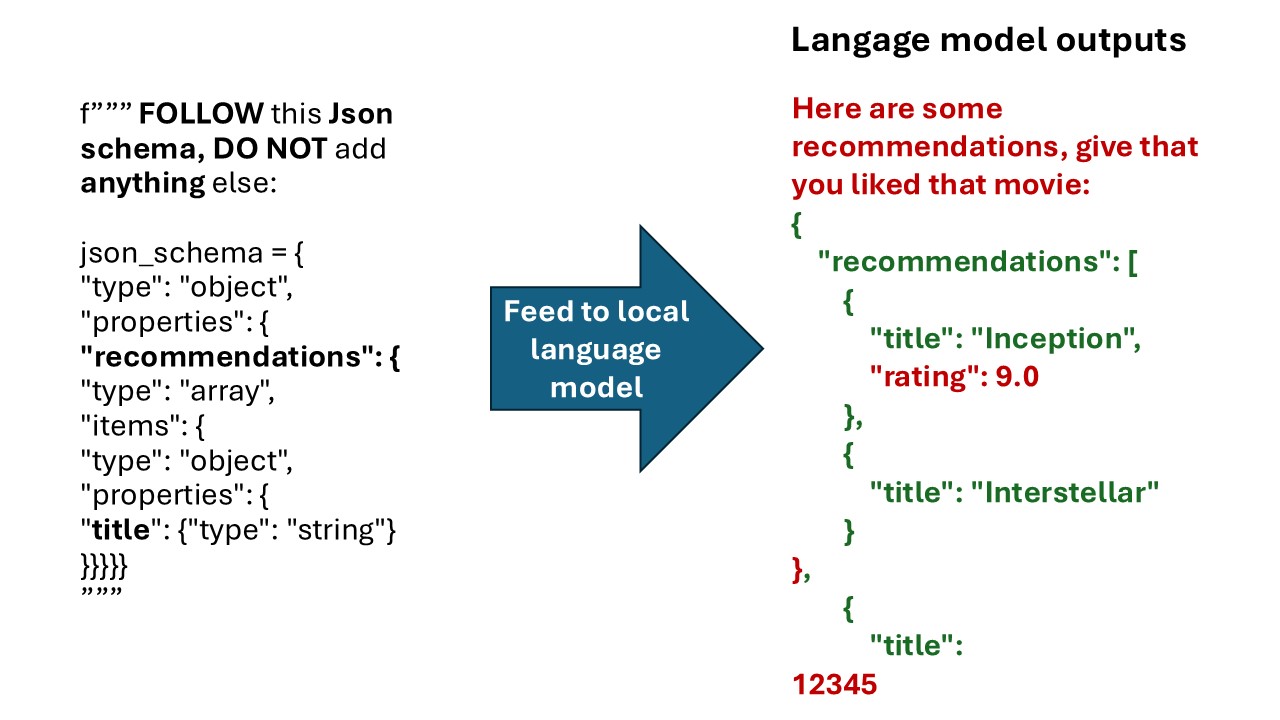
Pre-Structuring the Input
The first step is to provide the model with the structure directly, accompanied by a descriptive prompt if needed. Since we know the length of this prompt, it can be easily filtered out afterward. This approach effectively constrains the next-token prediction task to focus solely on generating the actual content:


This method is highly advantageous because it reduces the margin for error. Another significant benefit is computational efficiency: we no longer need to predict the entire structure autoregressively. Instead, only the final full-sequence prompt is processed by the model. (For more details, check out my previous blog on KV Cache to understand why this optimization is so impactful.)
Restraining the Output Space
We can further assist the model by restricting the set of possible predictions for the elements we want to fill. For example, if we have a predefined list of movies for the model to choose from, say: [The Dark Knight, The Dark Tower, The Godfather] the predictions can be visualized as a forest-like structure:


In this structure:
- Each yellow box represents a sampling phase.
- Blue nodes indicate the current state of the prediction.
- Edges represent the tokens likely to be predicted, along with their probabilities.
Tokens in red are eliminated during sampling, even if they were more likely, as they violate the predefined rules. Tokens in purple comply with the rules but are not selected because those in green have higher probabilities.
This approach also improves computational efficiency. If a token is the only valid descendant (e.g., “The Godfather” path), it can be directly selected, bypassing unnecessary computations.
Wrapping Up, But Not Quite
When reaching a leaf node, the output depends on whether additional rules have been set (e.g., the number of items to predict). For example, if no further rules are defined, the results might look like this:


In this case, we’ve performed two inference steps (reasoning). Since a leaf node has been reached, the rules are automatically applied (purple), further reducing computational requirements. No additional inference is needed, allowing us to move directly to the next item to predict.
Caveat
This approach is relatively straightforward and can be applied to models at any scale. However, the model’s fundamental ability to predict suitable sequences remains unchanged. The classic saying “garbage in, garbage out” still applies, but if you’re not careful, you may end up with “garbage in, perfumed garbage out.”
Practically Speaking
There are many libraries that implement this functionality out of the box. One of my favorites is guidance, which supports models hosted on Hugging Face and provides an impressive range of parameters to customize.
Here’s a snippet from their documentation to get you started:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
from guidance import models
lm = models.Transformers(model_name_or_path)
@guidance(stateless=True) # Note the stateless=True flag in the decorator -- this enables maximal efficiency on the guidance program execution
def character_maker(lm, id, description, valid_weapons):
lm += f"""\
The following is a character profile for an RPG game in JSON format.
```json
{{
"id": "{id}",
"description": "{description}",
"name": "{gen('name', stop='"')}",
"age": {gen('age', regex='[0-9]+', stop=',')},
"armor": "{select(options=['leather', 'chainmail', 'plate'], name='armor')}",
"weapon": "{select(options=valid_weapons, name='weapon')}",
"class": "{gen('class', stop='"')}",
"mantra": "{gen('mantra', stop='"')}",
"strength": {gen('strength', regex='[0-9]+', stop=',')},
"items": ["{gen('item', list_append=True, stop='"')}", "{gen('item', list_append=True, stop='"')}", "{gen('item', list_append=True, stop='"')}"]
}}```"""
return lm
character_lm = lm + character_maker(1, 'A nimble fighter', ['axe', 'sword', 'bow']) #