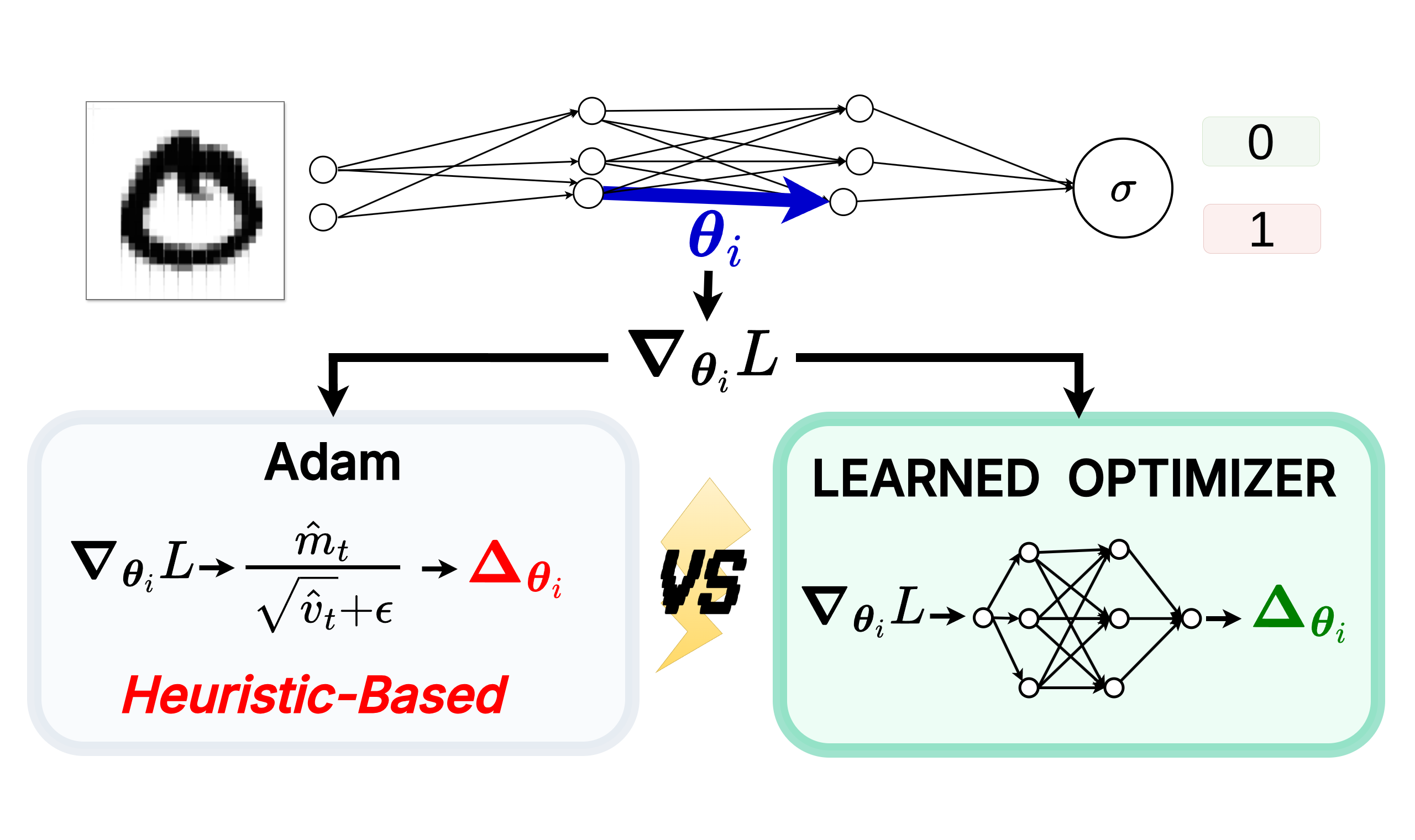
Towards a Bitter Lesson of Optimization: When Neural Networks Write Their Own Update Rules
We explore what can be the future of neural network parameter optimization
We explore what can be the future of neural network parameter optimization

Visualizing the hidden 3D geometry behind Layer Normalization and uncovering the mathematical trick that makes RMSNorm tick.
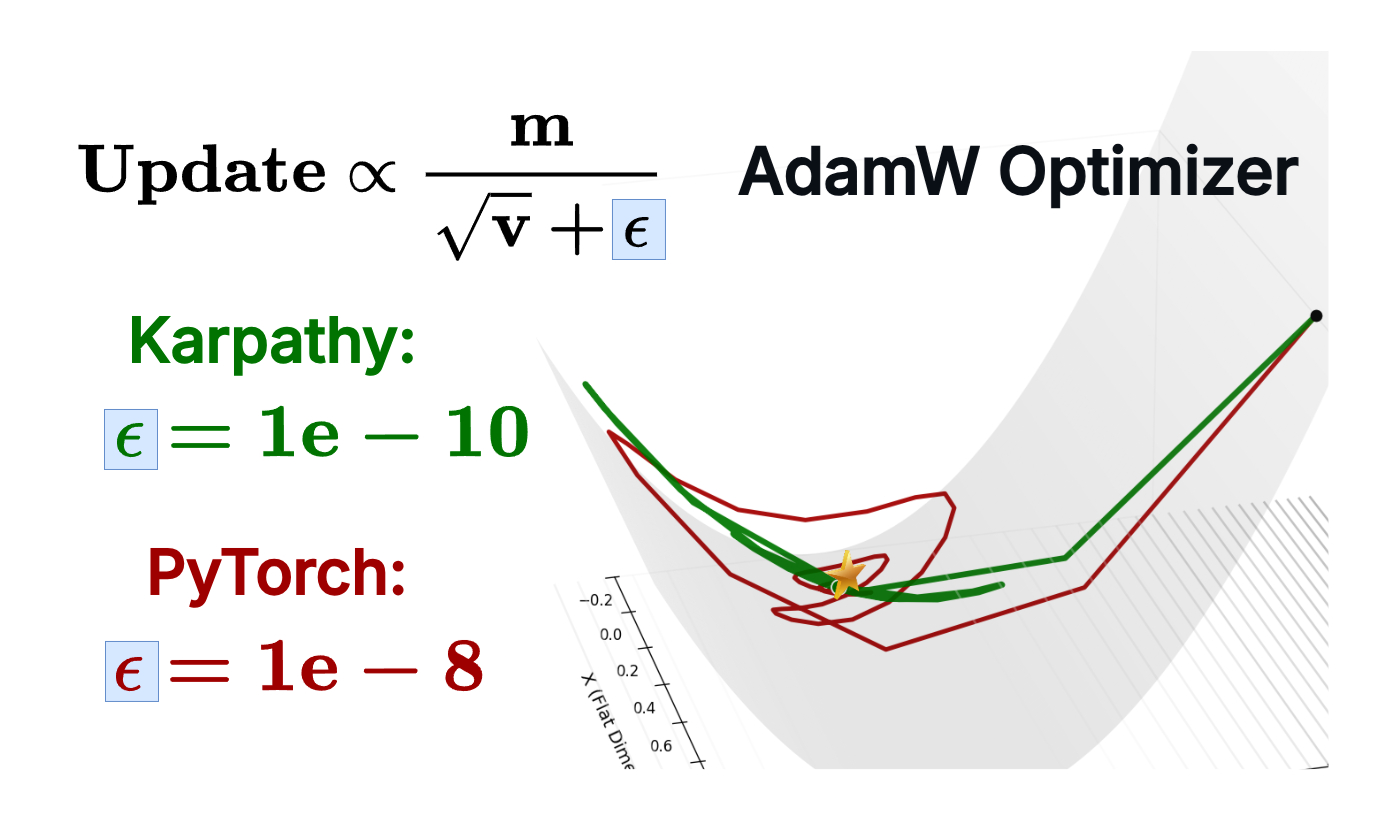
Beyond numerical stability, we investigate an often overlooked hyperparameter in the Adam optimizer: epsilon.
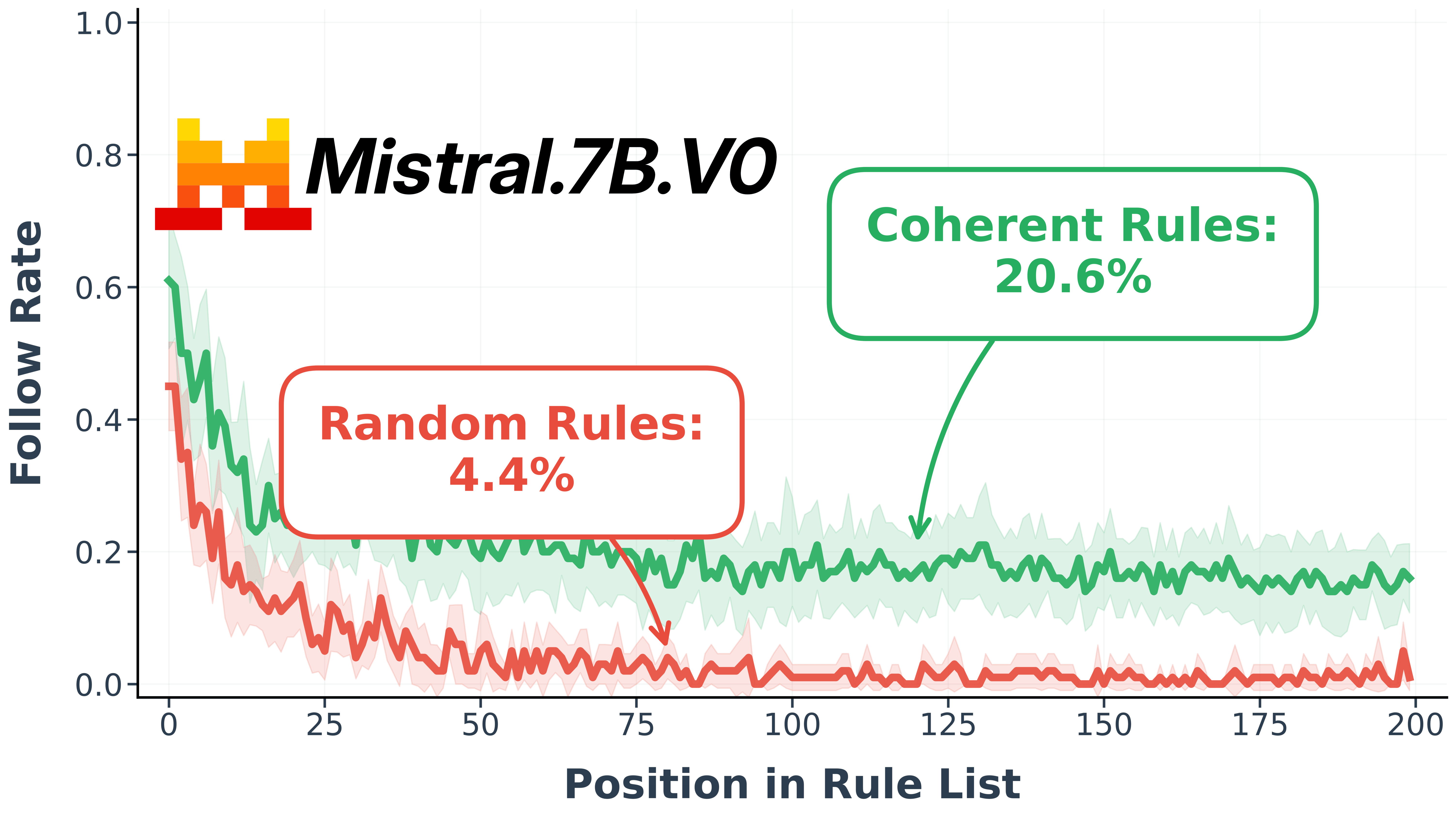
Testing whether semantic relatedness of instructions affects a model's ability to follow them under cognitive load
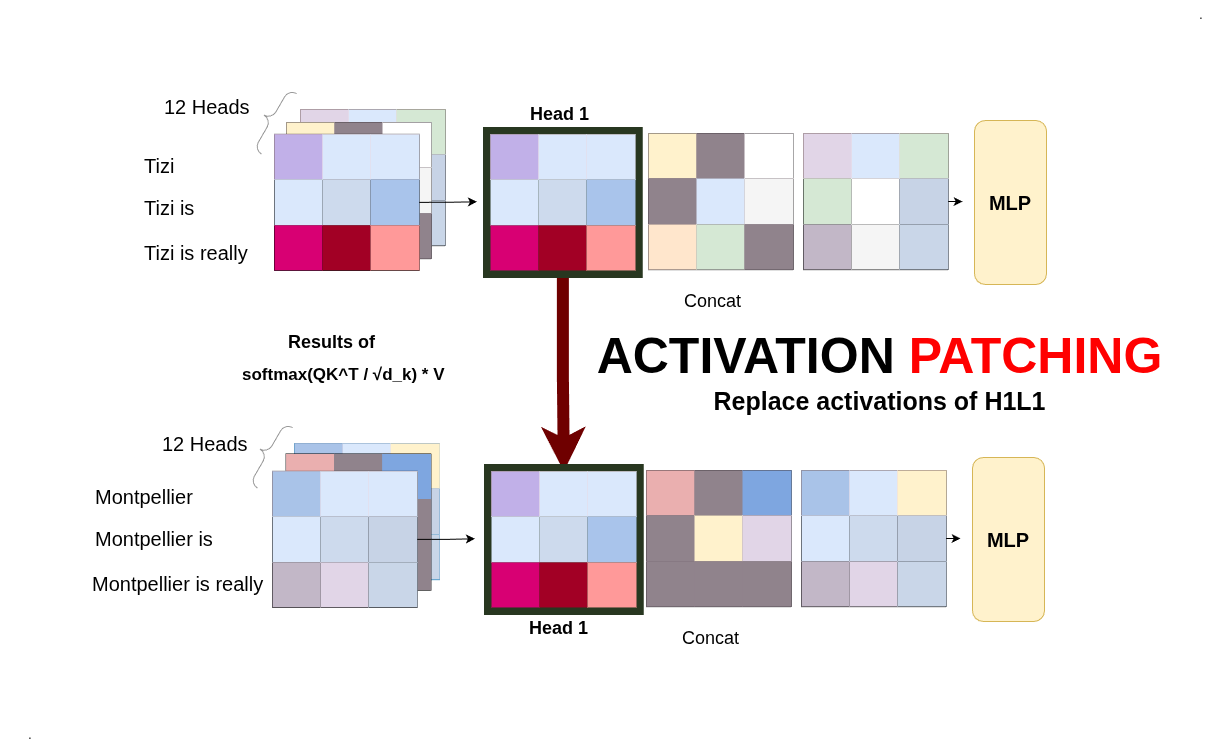
We strip down mechanistic interpretability to three key experiments: watching a model 'think', finding where it stores concepts, and performing 'causal surgery' to change its 'thought process'
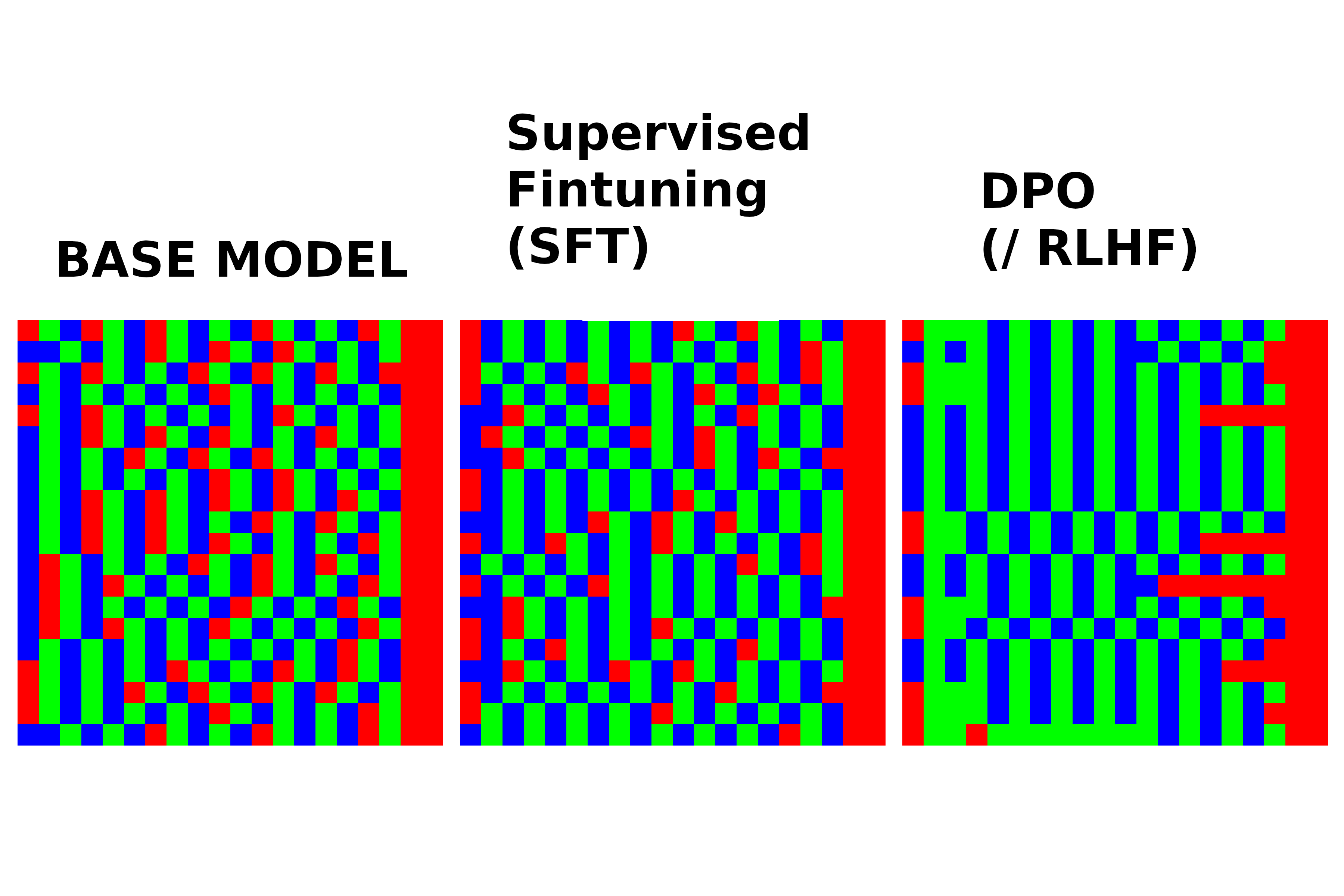
A visual guide and toy experiment to build intuition for the practical differences between Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO).
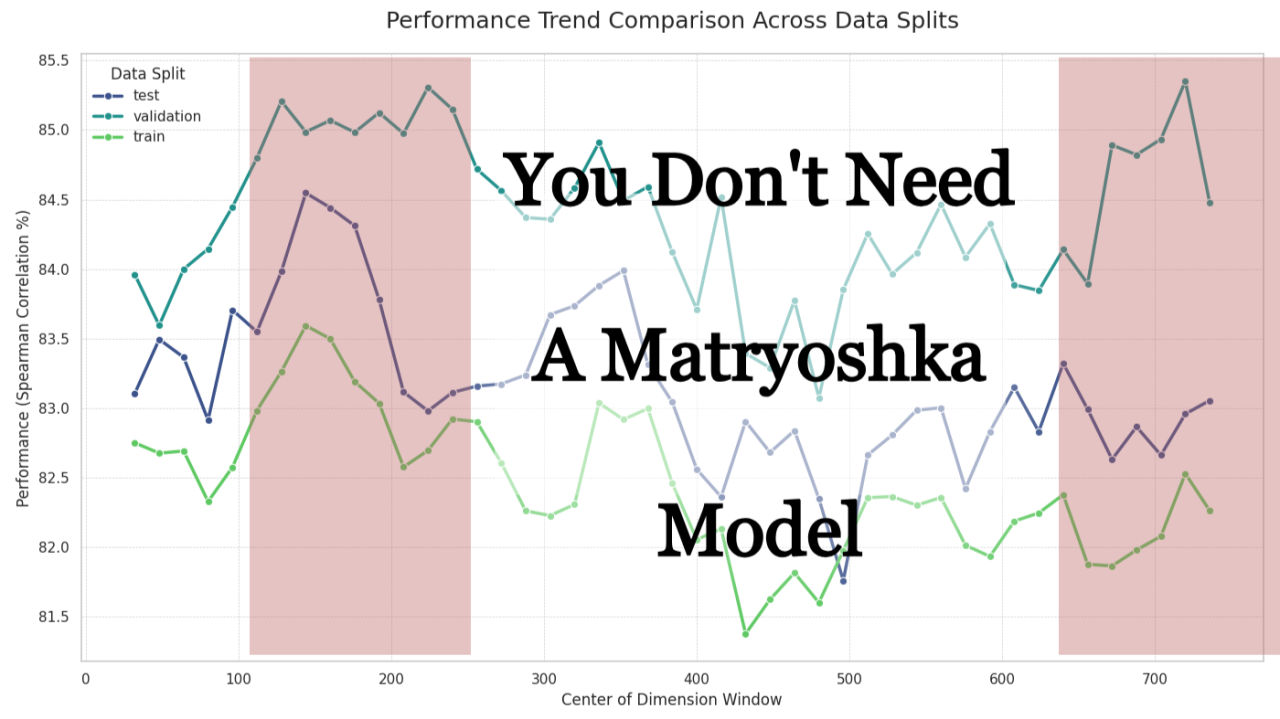
An analysis conducted on the informations hotspots on embeddings.

Flash Attention played a major role in making LLMs more accessible to consumers. This algorithm embodies how a set of what one might consider "trivial ideas" can come together and form a powerful s...

You've probably heard of the Transformers by now, they're everywhere, so much so that new born babies are gonna start saying Transformers as their first word, this blog will explore an important co...
If you're familiar with the Attention Mechansim, then you know that before applying a softmax to the attention scores, we need to rescale them by a factor of $\frac{1}{\sqrt{D_k}}$ where $D_k$ is t...