Speculative Decoding - Making Language Models Generate Faster Without Losing Their Minds
Speculative decoding speeds up autoregressive text generation by combining a small draft model with a larger verifier model. This two-step dance slashes latency while preserving quality, an essential trick for efficient LLM inference.

Accelerating LLMs with Speculative Decoding

Large Language Models (LLMs) are remarkable for their ability to generate human-like text, answer complex questions, and even write code. However, their inference phase (when they generate text) is often frustratingly slow. This is because LLMs operate autoregressively, predicting one token (a word or part of a word) at a time, with each token requiring a full forward pass through the model’s transformer architecture. For a 100-token sequence, that’s 100 computationally expensive passes, leading to noticeable delays.
Imagine writing a story where you must carefully choose each word one by one. It’s time-consuming! Now, picture having a helper who suggests several words ahead, and you only need to check if they fit. If they do, you move forward quickly; if not, you correct them. This is the essence of speculative decoding, a technique that significantly speeds up LLM inference without sacrificing quality.
Speculative decoding employs a two-model approach: a small, fast draft model guesses multiple tokens ahead, and a larger, more accurate verifier model evaluates these guesses in parallel. Correct tokens are accepted, while incorrect ones are discarded, and the verifier generates the right token. This method leverages the speed of the smaller model and the precision of the larger one, offering substantial efficiency gains.
Historical Context
Speculative decoding emerged from two pioneering papers developed independently, highlighting the urgency of addressing LLM inference bottlenecks:
- Leviathan et al. (2022): In their paper, Fast Inference from Transformers via Speculative Decoding, published on arXiv on November 29, 2022, Yaniv Leviathan and colleagues introduced speculative decoding. They used a smaller “approximation model” to propose tokens, which a larger target model verifies, achieving 2x–3x speedups on models like T5-XXL1.
- Chen et al. (2023): In Accelerating Large Language Model Decoding with Speculative Sampling, published on arXiv on February 2, 2023, Charlie Chen and colleagues at DeepMind presented a similar approach called speculative sampling. They demonstrated 2–2.5x speedups on a 70 billion parameter Chinchilla model using a “draft model” and a modified rejection sampling scheme2.
These papers, developed concurrently, share the core idea of using a smaller model to speculate tokens and a larger model to verify them, ensuring the output matches the target model’s distribution. In a revised version of their paper (May 18, 2023), Leviathan et al. acknowledged Chen et al.’s work as an independent implementation, underscoring the simultaneous innovation. This convergence reflects how critical the inference latency problem was, driving multiple teams to similar solutions.
Why Speculative Decoding Works
LLMs often become more predictable after generating a few tokens, especially in factual or structured outputs. For example, after “The capital of France is,” the next token is likely “Paris.” A smaller draft model can frequently guess these predictable tokens correctly. The draft model acts like a driver, proposing tokens quickly, while the verifier model serves as the brakes, ensuring accuracy by rejecting incorrect guesses. This synergy allows speculative decoding to capitalize on the strengths of both models.
Step-by-Step Breakdown
Here’s how speculative decoding works in detail:
- Drafting Tokens: The draft model takes the current context (e.g., “Once upon a”) and generates a sequence of k potential tokens (e.g., “time there was a king”).
- Verification via One-Pass Causal Masking: The verifier model, typically a larger transformer, processes the entire sequence (context + drafted tokens) in a single forward pass. Thanks to causal masking, each output logit at position t depends only on tokens 1 to t-1, allowing the model to compute the probability distribution ($ p_{\text{target}}(x \mid x_{1:n}, \tilde{x}_{n+1:t-1}) $) for each t simultaneously.
- Acceptance/Rejection: The verifier evaluates each drafted token using one of several criteria:
- Greedy Mode: Accept if the drafted token ($ \tilde{x}_{n+i} $) is the most probable, i.e., ($ \tilde{x}_{n+i} = \arg\max_x$ , $p_{\text{target}}(x \mid x_{1:n}, \tilde{x}_{n+1:i-1}) $).
- Top-k Mode: Accept if $( \tilde{x}_{n+i} )$ is among the top-k tokens by probability.
- Speculative Sampling: Accept with probability ($ A(\tilde{x}) = \min\left(1, \frac{p_{\text{target}}(\tilde{x})}{p_{\text{draft}}(\tilde{x})}\right) $). If rejected, sample from a residual distribution to maintain the target model’s distribution.
- Update Context: Accepted tokens are added to the context, and the process repeats..
Pseudocode
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# Draft k tokens using the draft model
x_draft = sample(draft_model, context, k)
# Verify with the large model
logits = large_model(context + x_draft)
probs = softmax(logits)
# Accept tokens until a rejection
accepted = []
for i, (x_i, p_i) in enumerate(zip(x_draft, probs)):
if x_i in top_k(p_i): # Simplified acceptance criterion
accepted.append(x_i)
else:
break
# Update context with accepted tokens
context += accepted
Why It’s Efficient
- Transformer Parallelism: Transformers compute logits for all tokens in parallel, enabling efficient verification.
- KV Caching: Cached key-value pairs for the context reduce computation for new tokens, making each verification pass faster.
Practical Implementation with Hugging Face Transformers
Here’s how to implement speculative decoding using Hugging Face Transformers:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load the target (main) model and tokenizer
# Using a smaller model (1.3B parameters) as the target for practicality
target_model_name = "facebook/opt-1.3b"
target_tokenizer = AutoTokenizer.from_pretrained(target_model_name)
target_model = AutoModelForCausalLM.from_pretrained(target_model_name, device_map="auto")
# Load the draft (assistant) model
# Using an even smaller model (125M parameters) as the draft
draft_model_name = "facebook/opt-125m"
draft_model = AutoModelForCausalLM.from_pretrained(draft_model_name, device_map="auto")
# Example prompt
prompt = "Lorem ipsum dolor sit amet, consectetur adipiscing"
# Encode the prompt into token IDs
input_ids = target_tokenizer.encode(prompt, return_tensors="pt").to(target_model.device)
# Generate text with speculative decoding
# The assisted_model parameter enables the draft model for speculation
output = target_model.generate(
input_ids,
max_length=50,
do_sample=False, # Deterministic generation for reproducibility
assistant_model=draft_model
)
# Decode the generated token IDs back to text
generated_text = target_tokenizer.decode(output[0], skip_special_tokens=True)
print('\nDraft model backed generation:')
print(generated_text)
# You can also compare with regular (non-speculative) generation
regular_output = target_model.generate(
input_ids,
max_length=50,
do_sample=False
)
regular_text = target_tokenizer.decode(regular_output[0], skip_special_tokens=True)
print("\nRegular generation:")
print(regular_text)
1
2
3
4
5
Draft model backed generation:
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut enim ad minim venenatis, sed do eiusmod tempor incididunt ut labore et dolore magna
Regular generation:
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut enim ad minim venenatis, sed do eiusmod tempor incididunt ut labore et dolore magna
I choose lorem ipsum precisely here because it has likely been seen and remembered by both models, thus also more likely to be validated by the main model, thus incurring a speedup :))
Practical Tips:
- Draft Model Selection: Choose a draft model 5–10x smaller than the target model to maximize speed while maintaining reasonable accuracy. For example, pair a 70B parameter target model with a 7B parameter draft model.
- Model Alignment: Use models with similar architectures (e.g., both based on LLaMA) and the same tokenizer to improve token acceptance rates.
- Alternative Libraries: Libraries like vLLM offer optimized speculative decoding implementations, reducing setup complexity.
Typical Throughput Speedups
A standard improvement of 2x to 3x in throughput is commonly reported when speculative decoding is applied with a well-chosen draft model and a large target model. For instance, Google’s original research and subsequent product deployments have consistently observed around 2x to 3x improvements in real-world LLM inference tasks, all while maintaining the same output quality3.
Recent Industry Benchmarks
NVIDIA’s TensorRT-LLM has demonstrated notable speedups with speculative decoding. On a single NVIDIA H200 GPU, using Llama 3.3 70B as the target model, speedups ranged from 2.6x to 3.5x, depending on the draft model’s size4. The chart below illustrates these gains with different draft models.
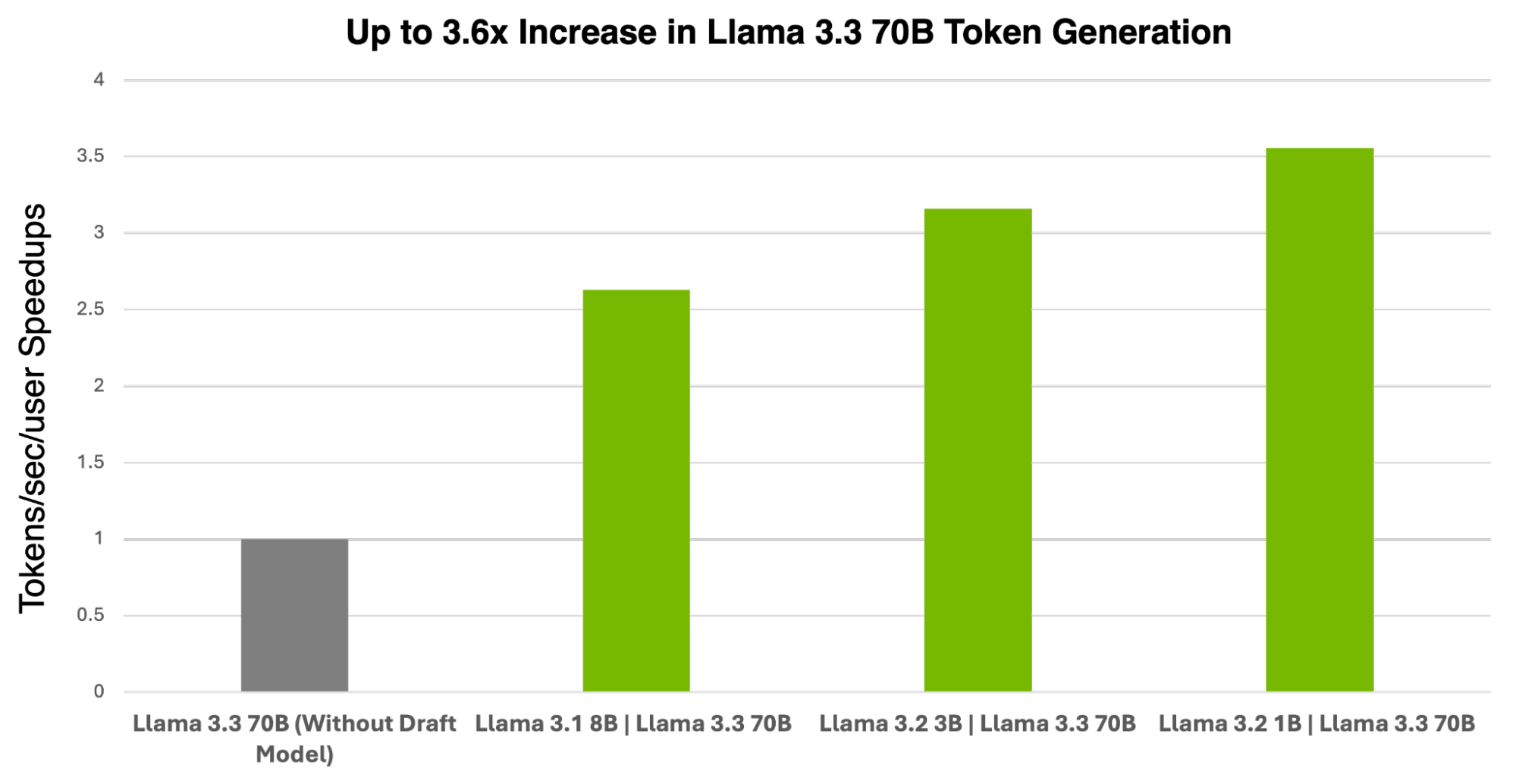
Source: NVIDIA Developer Blog, “Boost Llama 3.3 70B Inference Throughput 3x with NVIDIA TensorRT-LLM Speculative Decoding”
For larger models like Llama 3.1 405B, NVIDIA achieved even higher speedups of 3.0x to 3.6x on four H200 GPUs5. On consumer hardware, such as the Apple M3 Pro, benchmarks have shown speedups of 1.7x to 2.4x for programming and structured tasks, and 1.3x to 1.7x for more open-ended text generation6.
Limitations
- Draft Quality: A draft model too small may lead to low acceptance rates, wasting compute; too large, and speedups diminish.
- Sampling Compatibility: May not work well with techniques like temperature annealing or top-p sampling.
- Tokenizer Mismatch: Different vocabularies between models can disrupt speculation.
- Hardware Constraints: Bandwidth-limited systems may see reduced gains.
- Potential Bias: Misaligned draft models might introduce subtle biases, though verification mitigates this.
References
Leviathan, Y., et al. (2022). Fast Inference from Transformers via Speculative Decoding. ↩︎
Chen, C., et al. (2023). Accelerating Large Language Model Decoding with Speculative Sampling. ↩︎
Google Research. Looking Back at Speculative Decoding ↩︎
NVIDIA Developer Blog. Boost Llama 3.3 70B Inference Throughput 3x with NVIDIA TensorRT-LLM Speculative Decoding ↩︎
NVIDIA Developer Blog. TensorRT-LLM Speculative Decoding Boosts Inference Throughput by Up to 3.6x ↩︎
Amotivv. (2025). Speculative Decoding: Accelerating AI in 2025 ↩︎