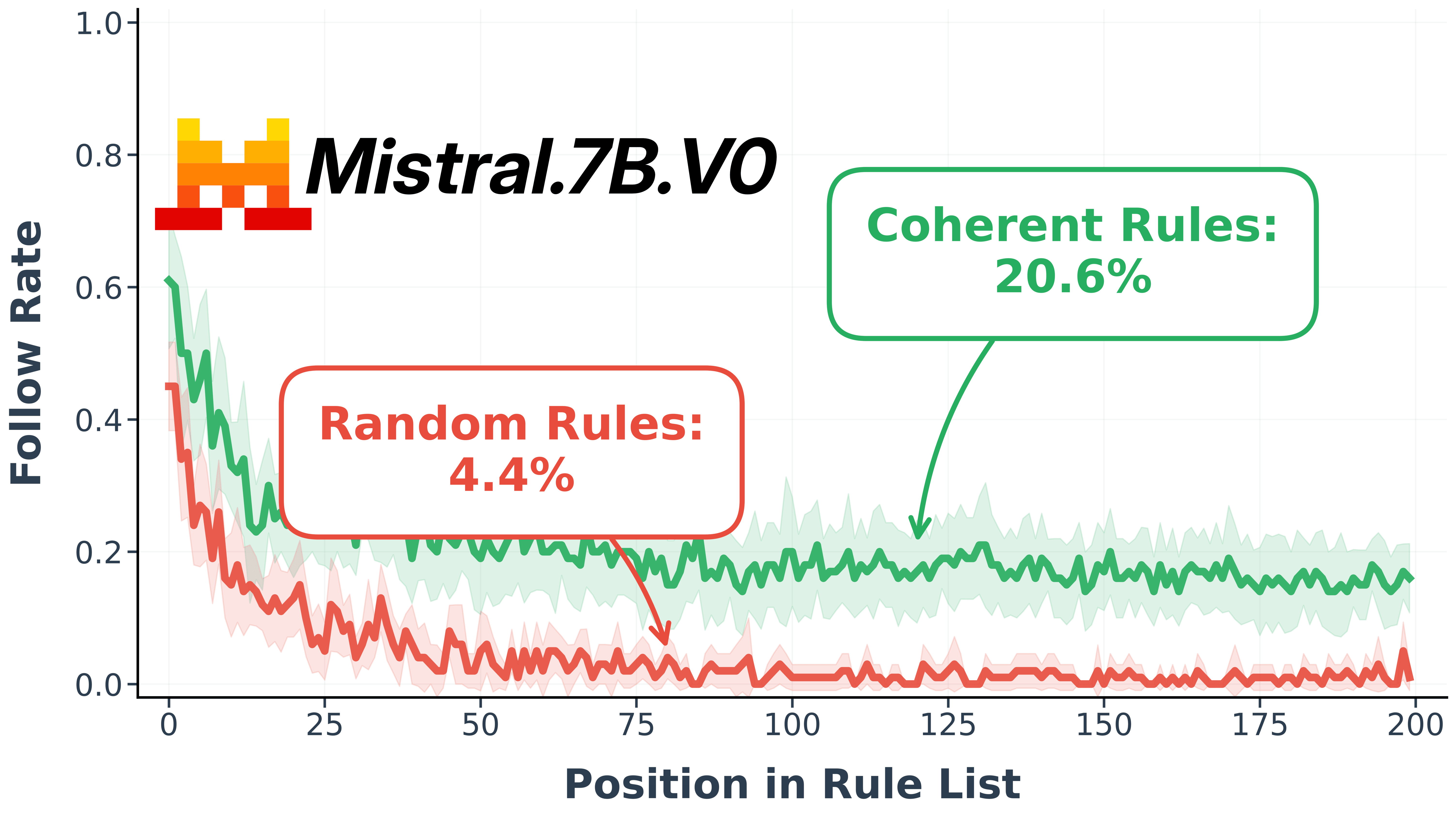
Entropic Instruction Following: Does Semantic Coherence Help LLMs Follow Instructions?
Testing whether semantic relatedness of instructions affects a model's ability to follow them under cognitive load
Testing whether semantic relatedness of instructions affects a model's ability to follow them under cognitive load
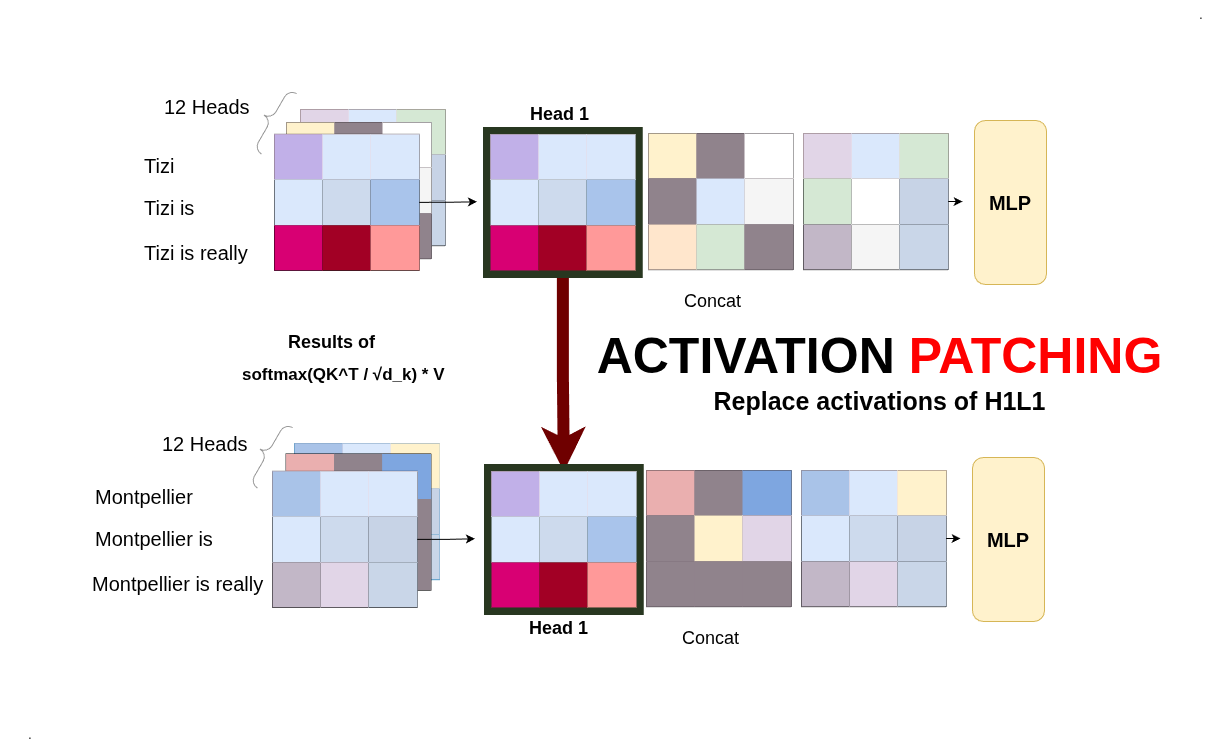
We strip down mechanistic interpretability to three key experiments: watching a model 'think', finding where it stores concepts, and performing 'causal surgery' to change its 'thought process'
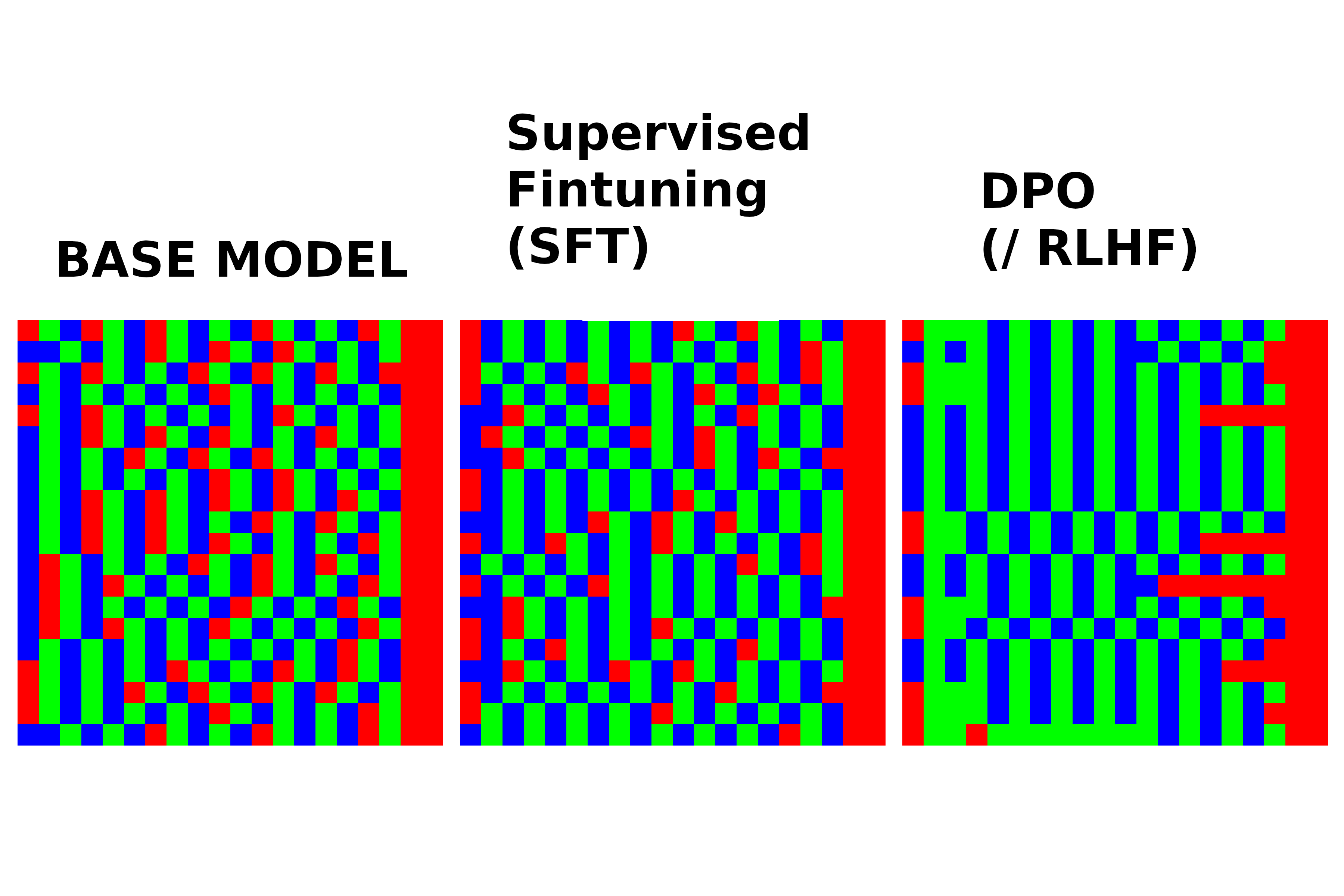
A visual guide and toy experiment to build intuition for the practical differences between Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO).
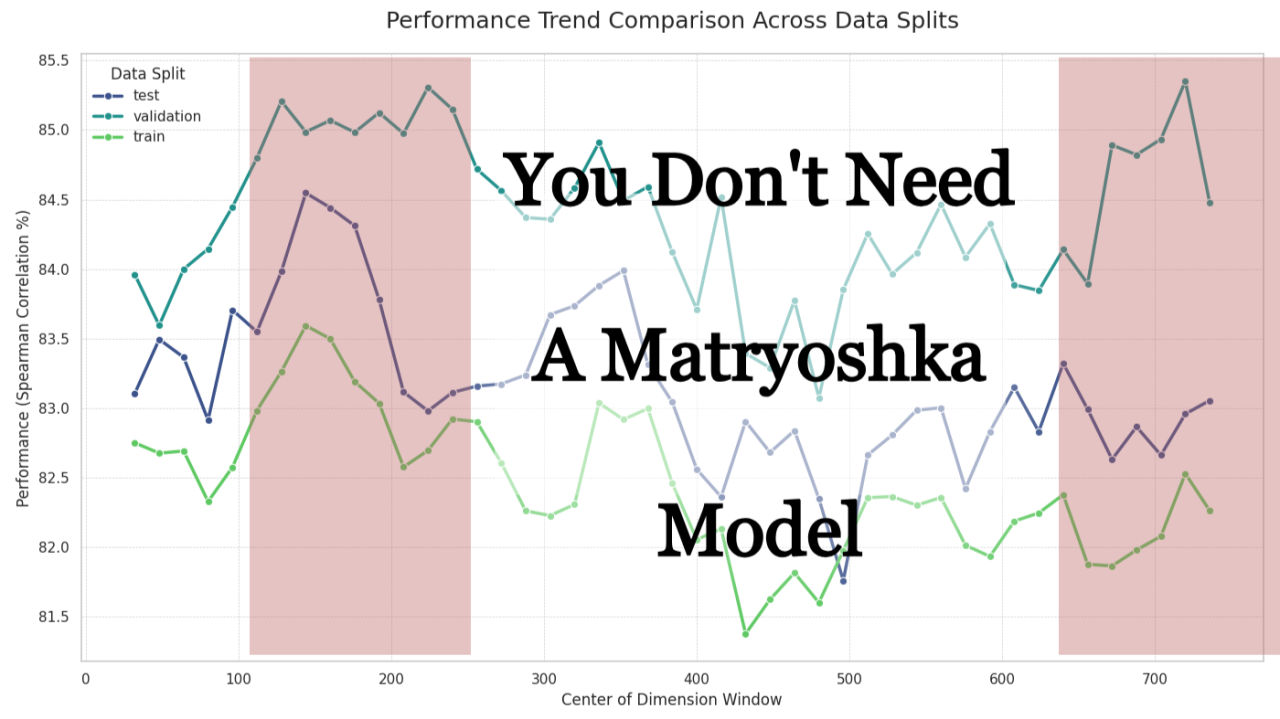
An analysis conducted on the informations hotspots on embeddings.

A comprehensive guide to chunking strategies for Retrieval-Augmented Generation, from basic splitting to advanced semantic and agentic approaches.

Speculative decoding speeds up autoregressive text generation by combining a small draft model with a larger verifier model. This two-step dance slashes latency while preserving quality, an essenti...

Mixture of Experts (MoE) lets you scale transformer models to billions of parameters without proportional compute costs. By selectively routing tokens through specialized experts, MoE achieves mass...

Flash Attention played a major role in making LLMs more accessible to consumers. This algorithm embodies how a set of what one might consider "trivial ideas" can come together and form a powerful s...
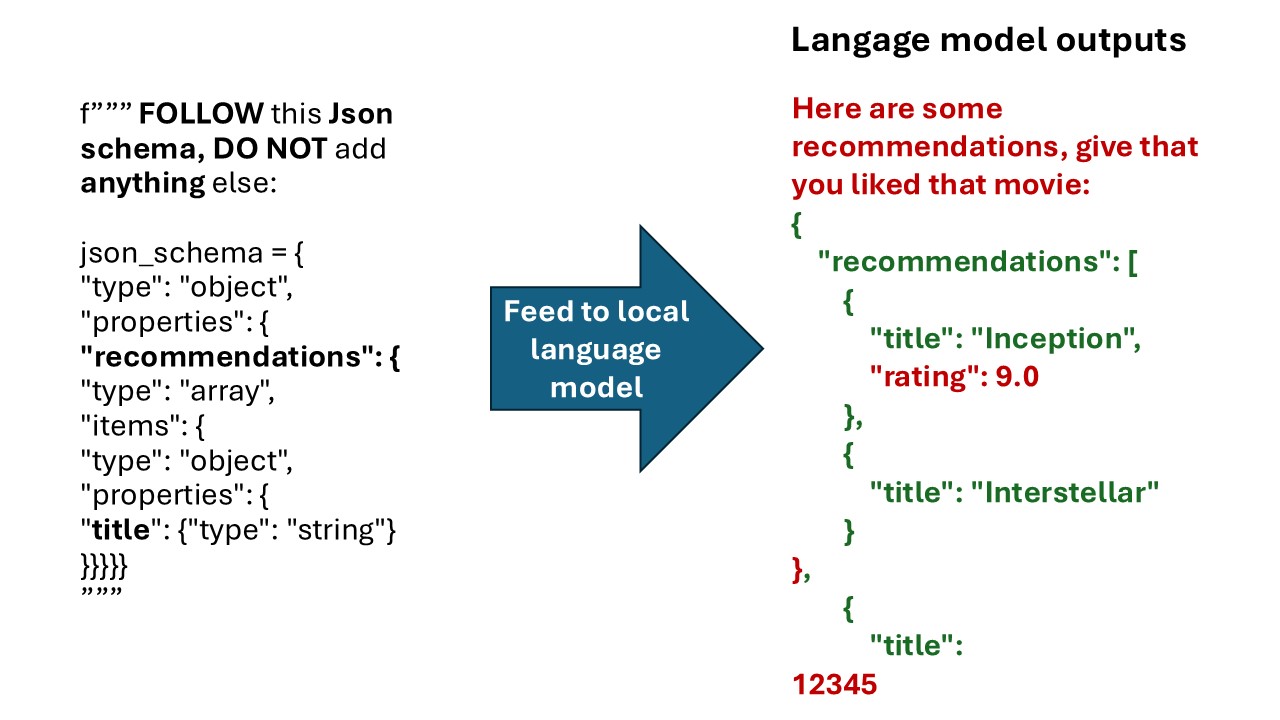
In this post, we explore how to simplify and optimize the output generation process in language models using guidance techniques. By pre-structuring inputs and restraining the output space, we can ...
/paligemma.png)
The amount of visual data that we constantly ingest is massive, and our ability to function in an environment may greatly impove when we have access to this modality, thus being able to use it as a...