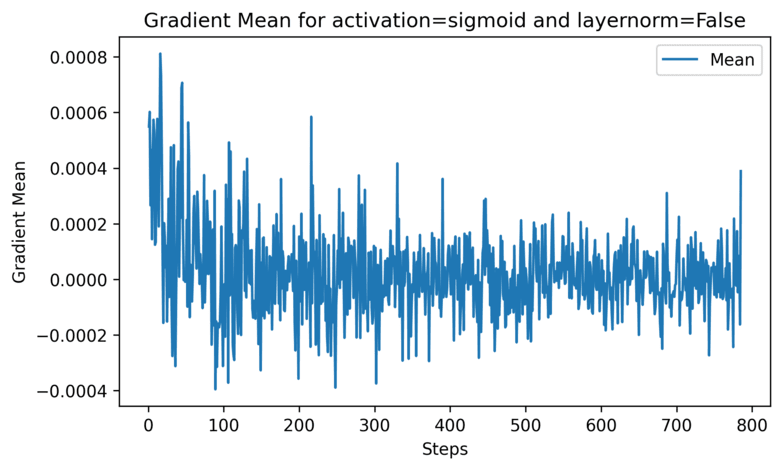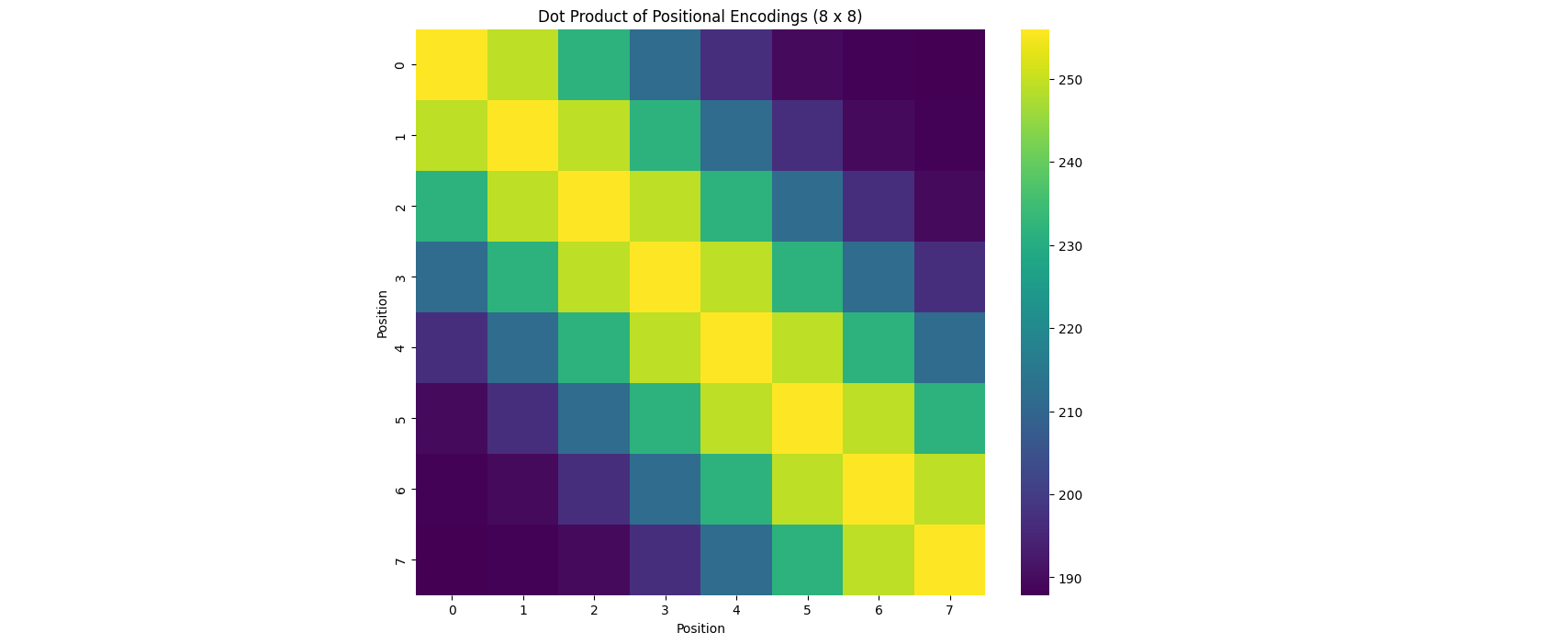
The Hidden Beauty of Sinusoidal Positional Encodings in Transformers
In this blog we will shed the light into a crucial component of the Transformers architecture that hasn't been given the attention it deserves, and you'll also get to see some pretty vizualizations!



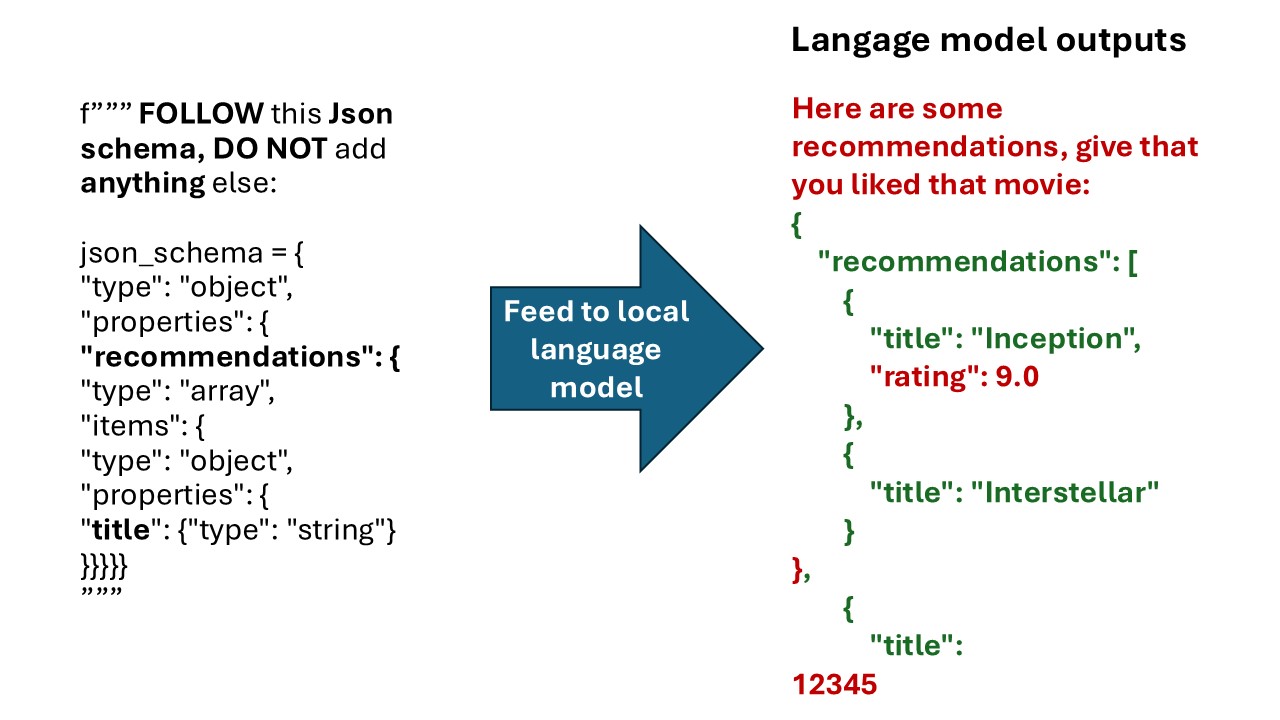
/paligemma.png)